App Cloud
Costruisci lo stack ELK con Elasticsearch
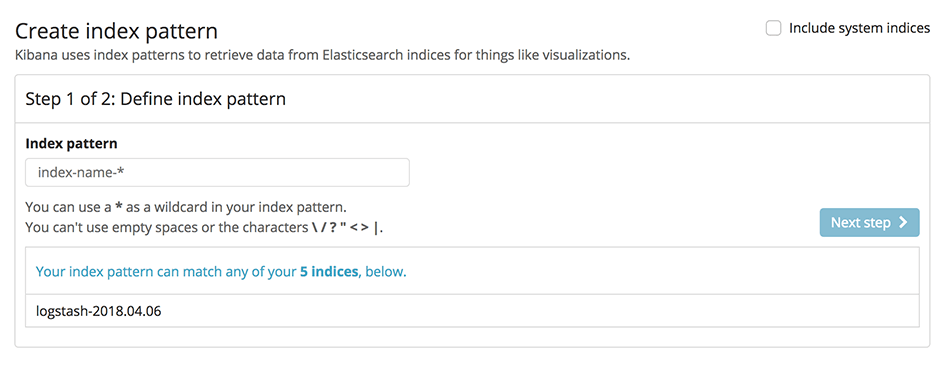
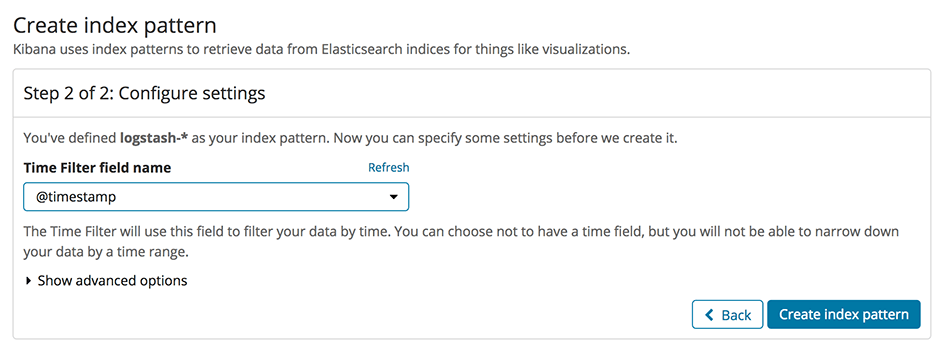
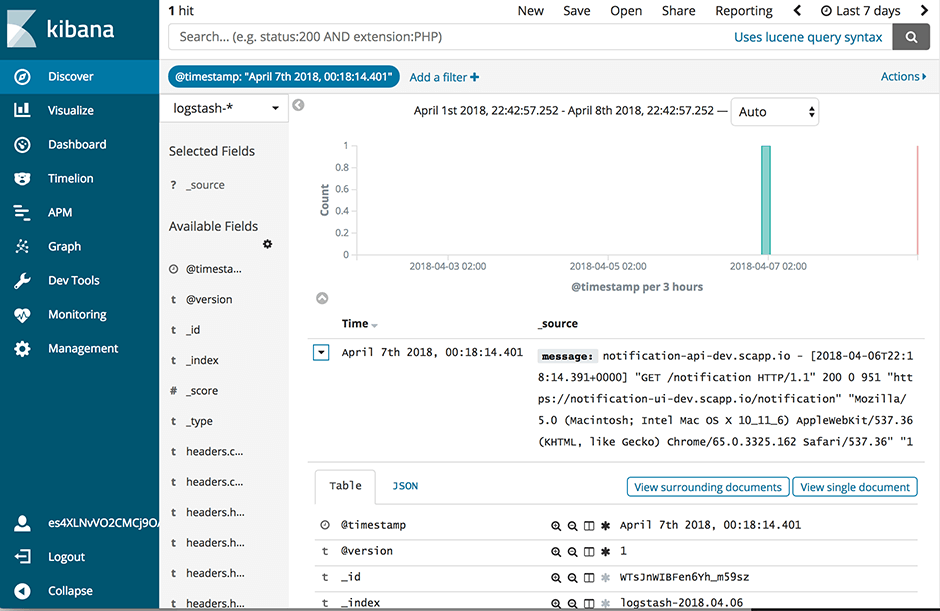
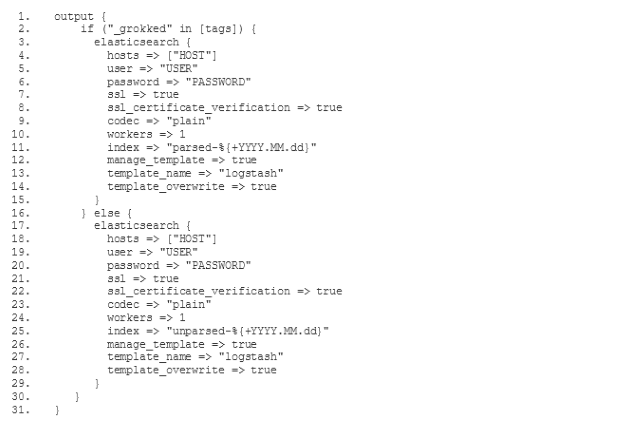
Abbiamo lanciato il nostro nuovissimo servizio Elasticsearch su Swisscom Application Cloud (in versione beta chiusa al momento in cui scriviamo, ma la disponibilità generale è imminente). Questo servizio sostituisce la nostra vecchia offerta ELK con opzioni più stabili e flessibili. In questo post ti mostreremo come utilizzare Elasticsearch insieme ai buildpack Logstash e Kibana per ottenere lo stack ELK che già conosci. Ti daremo anche alcuni spunti su come utilizzare la maggiore flessibilità dell'offerta per personalizzare lo stack in base alle tue esigenze.