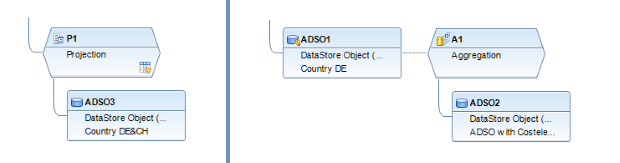
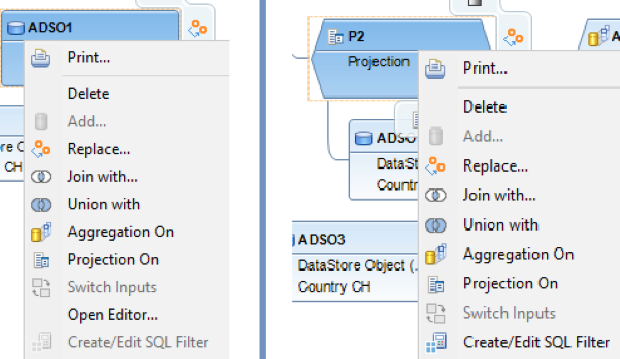
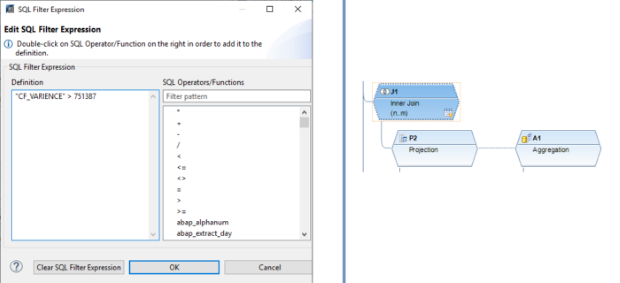
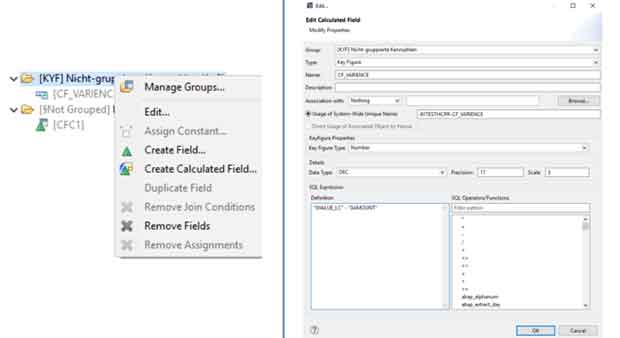
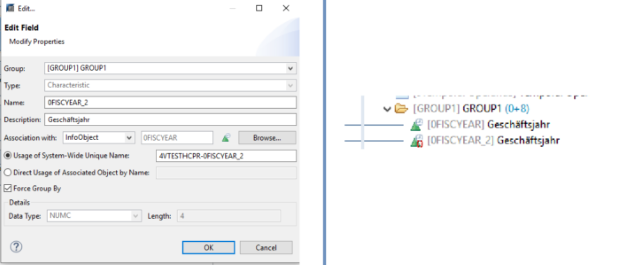
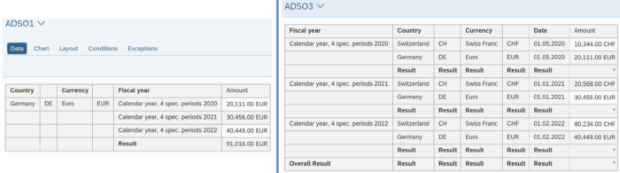
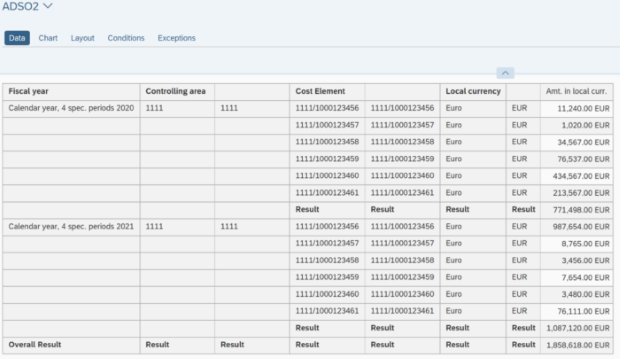
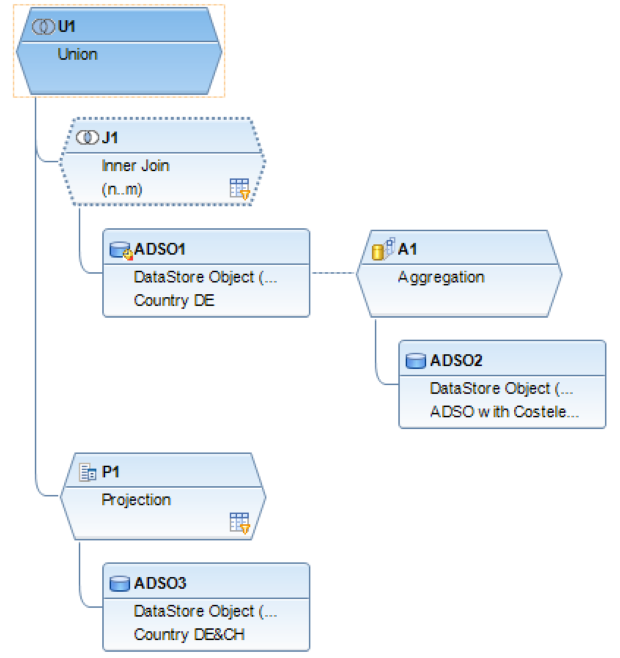
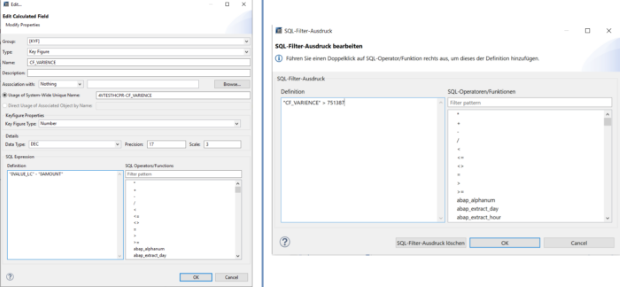
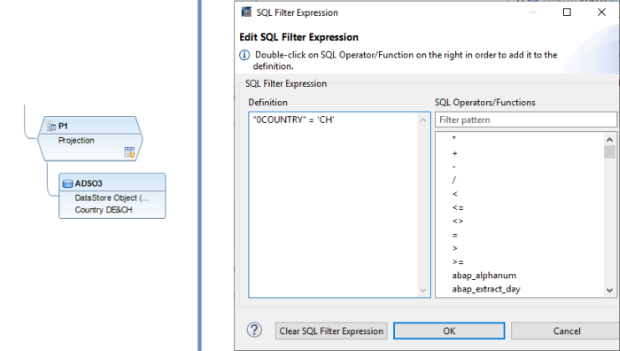
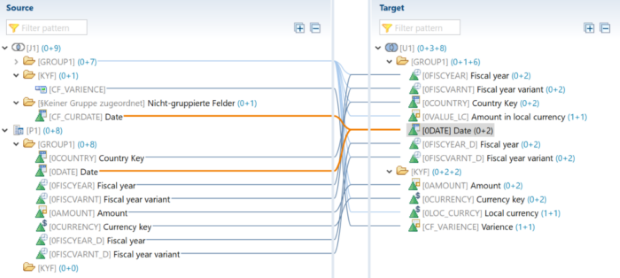
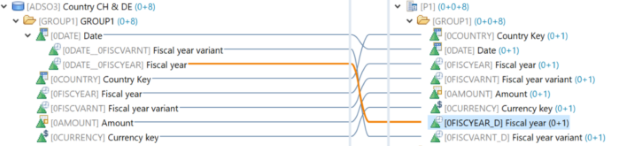
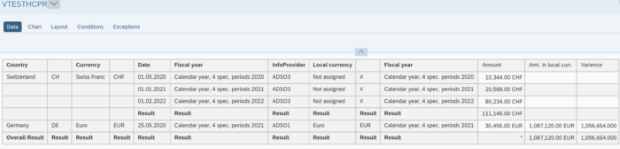
Der SQL-Filter ist ein leistungsstarkes Werkzeug, mit dem du bestimmte Daten aus dem gesamten CompositeProvider oder seinen PartProvidern herausfiltern kannst. Er ermöglicht die Erstellung zusätzlicher Filter auf verschiedenen Knotenebenen eines CompositeProviders. Direkt auf dem Top Node oder auf seinen verschiedenen Teilen, wie zum Beispiel auf bestimmten Unions, Joins, Projektionen und Aggregationen darunter. Solche Filter können jedoch nicht direkt auf einem PartProvider definiert werden. Daher muss ein Aggregations- oder Projektionsknoten über ihm hinzugefügt werden, um diese Funktion zu ermöglichen. In einem SQL-Filter können sowohl berechnete Felder als auch normale Felder verwendet werden, um einen Ausdruck zu bilden. Für diese Zwecke wird die HANA SQL-Skriptsprache verwendet. Eine Liste der verfügbaren Ausdrücke wird angezeigt, wenn du sie auswählst. Es gibt bereits eine umfangreiche HANA SQL Script-Referenz, die du hier(öffnet ein neues Fenster) einsehen kannst.