Die Technologie, die von Unternehmen übernommen wurde, um all diese riesigen Datenmengen aller Art zu speichern, endete als Data Lake. Diese Technologie kann jede Art von Daten, ob strukturiert oder unstrukturiert, in ihrem Rohformat speichern. Und das erreicht es dank der Trennung von Daten und dem Schema, das sie definiert. (Schema-on-read) [6]. Traditionell werden Geschäftsdaten in strukturierten Datensystemen mit einem Schema gespeichert, das bei der Datenerfassung vorgegeben wird. Auf der anderen Seite speichern Data Lakes jede Art von Daten im Rohformat, um Daten aus verschiedenen Quellen zu replizieren, die später vorverarbeitet, aggregiert, kombiniert und interpretiert werden.
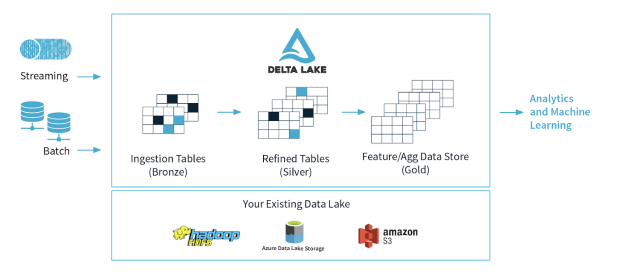
Ein richtig konzipierter Data Lake sollte aus drei Hauptbereichen bestehen. Dabei handelt es sich um Bronze (zum Klonen aller Arten von Daten im Rohformat), Silber (Daten werden verfeinert: vorverarbeitet, gereinigt und gefiltert) und Gold (kombiniert, aggregiert für den Geschäftsnutzen) [8]. Zusätzliche Bereiche könnten in Betracht gezogen werden, um andere Prozesse zu trennen, die für die Art des Geschäfts und die Anforderungen spezifisch sind. Unternehmen beginnen die Probleme zu erkennen, die bei dieser Art von Architektur auftreten, welche nur auf Data Lake basiert, daher erleben sie eine Reihe von Problemen und Herausforderungen, wenn sie Daten analysieren oder in erweiterten Berichten verwenden möchten.
Data Lake ist nicht für die Unterstützung von Transaktionen oder Metadaten ausgelegt. Es erfordert eine Reihe zusätzlicher Fähigkeiten, um sie auszuführen, zu verwalten und zu steuern. Data Lakes verarbeiten keine beschädigten, unvollständigen oder qualitativ minderwertigen Daten. Es ist auch nicht darauf ausgelegt, Batch-Daten und Streaming-Verarbeitung zu kombinieren. Sie berücksichtigen keine unterschiedlichen Versionen von Daten oder Schemaänderungen. Letzteres kann in der Tat die Daten völlig unbrauchbar machen. Darüber hinaus beschlossen einige Unternehmen, regelmäßig vollständige Kopien der Datenquellen zu planen, wodurch mehr Ressourcen verbraucht wurden, um sie zu speichern und zu verarbeiten.
Die aktuelle Realität ist, dass viele Data Lakes für viele Unternehmen zu Data Swamps [11] geworden sind. Ein Ort, an dem alle Arten von Daten nebeneinander existieren, ohne dass der Benutzer es weiss, was gespeichert wird und ob ihre Qualität mit dem Inhalt der ursprünglichen Quellen übereinstimmt. All dies macht einen Großteil der Data Lakes fast unbrauchbar. Die Aufzeichnung von Daten ohne Onboarding-Prozess oder eine Sicht auf ihre mögliche Verwendung macht es noch schwieriger. Aus Sicht der KI / ML werden diese Data Lakes, wenn sie zur Erstellung fortschrittlicher Modelle verwendet werden, zu einer Quelle von Garbage In / Garbage Out, wie es umgangssprachlich bekannt ist. Außerdem haben Unternehmen erkannt, dass Daten auf diesen Systemen mit einer höheren Rate wachsen, als ihre Computersysteme analysieren können.