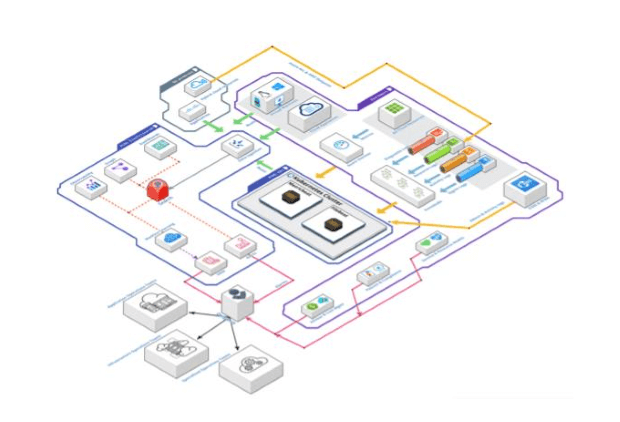
Die erste Ebene, die Telemetrie, befindet sich auf der rechten oberen Seite. Dazu gehören Datenquellen unserer Public Cloud-Kunden, wie z.B. verschiedene Arten von Protokollen der PaaS- und SaaS-Cloud-Ressourcen, z.B. Aktivitätsprotokolle oder Anmeldeprotokolle, die mit EventHub erfasst werden, und deren Metriken, die von Azure Monitor gesammelt werden. Darüber hinaus senden die IaaS-Ressourcen ihre Metriken und Protokolle mithilfe von Beats-Agenten direkt an unseren Elastic Stack und erfassen auch die Verwaltungs- und Aktivitätsprotokolle der Cloud-Angebote von O365 und M365, um Lösungen für die Beobachtung und das Monitoring der Cloud-Arbeitsplatz-Domain bereitzustellen. Zu guter Letzt ist der Trend zu hybriden Szenarien zu nennen, bei denen unsere Kunden ihre verschiedenen Clouds und On-Premises-Infrastrukturen miteinander verbinden. Wir erfassen Protokolle und Metriken bestimmter Betriebsmittel, manchmal direkt und manchmal über öffentliche Cloud-Angebote wie Azure Arc und AWS Outpost.