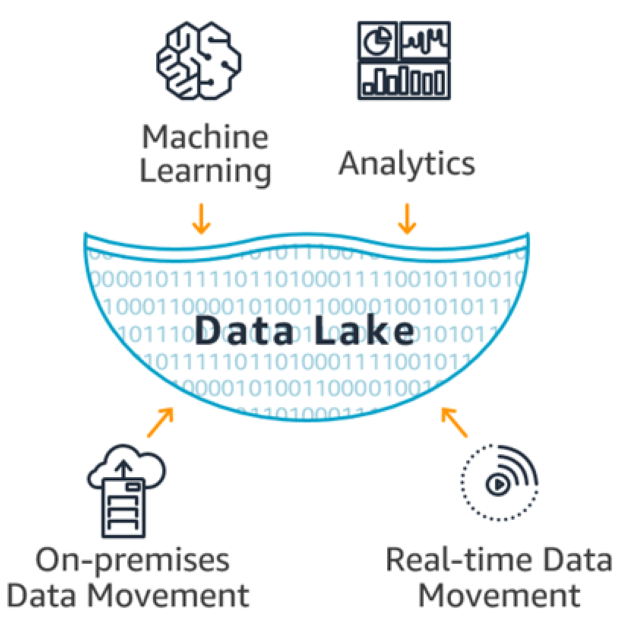
Big data analytics aims to process huge amounts of structured and unstructured data to gain valuable insights for the organisation. It looks for correlations and underlying patterns that are not obvious to humans but are uncovered by AI (artificial intelligence), machine learning technologies and distributed computer systems.
A second digital transformation is taking place that is even deeper and more relevant to our lives than we have experienced in recent decades. This digital transformation is not only concerned with the creation of digital services, but also with the transformation of everything we know into digital replicas (as in digital twins, metaverse, IoT (Internet Of Things)). In particular, the use of big data analytics, helps to analyse all kinds of data that can help us, our business and our lives to improve.
The big catalyst for this true digital transformation has been the pandemic, which has forced not only businesses but also most people to keep up with the latest digital technologies. According to a recent survey, 67% of respondents said that they have accelerated their digital transformation and that 63% have increased digital budgets due to the pandemic [7]. This acceleration of digital transformation can be seen in healthcare (AI-driven reporting, electronic medical records, pandemic predictions, etc.), but also in many other sectors. The use of advanced analytics to understand the latest trends due to the pandemic and remote working has become increasingly important. Companies have adapted their digital services and digital strategies to this new reality. For this reason, the growth of the digital market and big data analytics is expected to experience even greater momentum in the coming years.
It wasn't so long ago that big data and AI technologies became popular with companies. All companies wanted to enter this new era of intelligent insights. So they started collecting all kinds of traditional business data, but also device data, logs, text files, documents, images, etc. in one place. In the hope that these new technologies could extract insights from all this big data with little effort and be relevant to businesses. All of this happened, either due to the lack of maturity of companies in terms of big data technologies or because they did not have a clearly defined big data strategy.