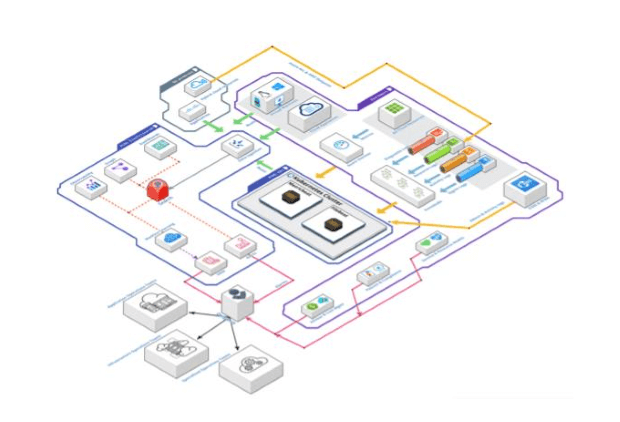
We have the first layer, telemetry, in the top right-hand-side . This includes data sources of our public cloud customers, like different types of logs of the PaaS and SaaS cloud resources, e.g. activity logs or sign-in logs gathered using EventHub and their metrics gathered from Azure Monitor. In addition, we have the IaaS resources sending their metric and logs using Beats agents directly to our Elastic stack, and also grab the administrative and activity logs of O365 and M365 cloud services to provide observability & monitoring solutions for deliver cloud workplace domain. Last but not the least is the upcoming trend of hybrid scenarios, where our customers are connecting their multiple clouds and on-premises infrastructure, we gather logs and metrics of certain resources, at time directly and sometimes via public clouds route; this is when customers are using public cloud services like Azure Arc and AWS outpost.