Business Intelligence
Die Föderation von Trino
Eine Antwort auf die Spannungen zwischen Informationstrennung und -integration.
Von Joel Welti, Senior Data & Analytics Consultant
Business Intelligence
Eine Antwort auf die Spannungen zwischen Informationstrennung und -integration.
Nun, Trino ist eine halbe Datenbank, das ist es, was es ist. Und obwohl viele das für ziemlich seltsam und nutzlos halten, ist genau das eine seiner größten Stärken. Trino ist eine Datenbank, in der keine Daten gespeichert sind. Deshalb wird es auf der Website auch nicht als Datenbank, sondern als SQL-Abfrageprogramm vorgestellt:
Trino ist eine verteilte SQL-Abfrage-Engine, die für die Abfrage großer Datensätze entwickelt wurde, die über eine oder mehrere heterogene Datenquellen verteilt sind.
Das bedeutet, dass Trino sich wie eine Datenbank verhält, aber das tut es, indem es Daten verarbeitet, die so ziemlich überall gespeichert sind, nur nicht in ihm selbst. Deshalb ist es nur zur Hälfte eine Datenbank. Und das ist interessant, denn die klassische relationale Datenbank arbeitet fast ausschließlich mit Daten, die in ihr selbst gespeichert sind, und der Zugriff auf die in ihr gespeicherten Daten erfolgt ausschließlich über ihre eigene Software. Trino greift erstens fast überall auf Daten zu (sieh dir die lange und wachsende Liste der Konnektoren zu anderen Technologien an), und zweitens können diese Daten auch direkt von anderen Systemen abgerufen werden. Das macht Trino integrierter, ja sogar integrativer. Wenn du zwei oder mehr Konnektoren zu verschiedenen Systemen hast, kannst du auch "innerhalb einer einzigen Abfrage auf Daten aus mehreren Systemen zugreifen. Verbinde zum Beispiel historische Protokolldaten, die in einem S3-Objektspeicher gespeichert sind, mit Kundendaten, die in einer relationalen MySQL-Datenbank gespeichert sind." (trino.io) Das nennt man Query Federation (siehe den Titel dieses Artikels). Das ist kein Allheilmittel und kann sich auf die Abfrageleistung auswirken, was auch vom Quellsystem abhängt, aber es kann manchmal eine gute Option sein.
Wenn wir nun in der Geschichte der (analytischen) IT zurückgehen, stellen wir zunächst fest, dass dieses Konzept der Trennung von Speicherung und Berechnung für Datenbanken gar nicht so neu ist. Tatsächlich gibt es dieses Konzept schon sehr lange, aber in der Analytik ist es viel stärker in den Vordergrund gerückt, wahrscheinlich beginnend mit Hadoop, das erstmals 2006 veröffentlicht wurde.
Der Kern von Apache Hadoop besteht aus einem Speicherteil, bekannt als Hadoop Distributed File System (HDFS), und einem Verarbeitungsteil, der ein MapReduce-Programmiermodell ist.
Die Begriffe "Berechnung", "Verarbeitung" und auch "Ausführung" sind in diesem Zusammenhang synonym. Trino verarbeitet, wie wir bereits erwähnt haben, Daten, aber die Daten werden nicht in sich selbst gespeichert.
Im Gegensatz zu Hadoop ist Trino definitiv und umfassend SQL first. Der Titel des ursprünglichen Whitepapers lautet sogar "Presto: SQL für alles". Moment, was ist "Presto"? Presto ist der ursprüngliche Name des Projekts, das jetzt Trino heißt. Und hier gibt es eine traurige Geschichte zu erzählen. Das Presto-Projekt wurde 2014 bei Facebook gestartet. Aber die ursprünglichen Entwickler und Facebook trennten sich 2018 wegen Fragen der Verwaltung und Kontrolle über das Open-Source-Projekt. Die lange Geschichte findest du hier. Im Wesentlichen gibt es jetzt Trino und Presto, die in zwei getrennten Projekten fast die gleiche Software entwickeln. Und obwohl manchmal Code zwischen den beiden geteilt wird, hat diese Spaltung den Fortschritt mit Sicherheit behindert. Außerdem stellt sich natürlich die Frage: Welches soll man benutzen? Ein klarer Fall von gleich und doch anders. Wir können den Puls der beiden Repos auf GitHub vergleichen und zu dem Schluss kommen, dass das Trino-Projekt (mit den ursprünglichen Entwicklern) immer noch stärker ist als das Presto-Projekt (das Facebook nach dem Fallout an die Linux Foundation übertragen hat). Das ist natürlich nicht die genaueste Wissenschaft, aber zusammen mit dem Vergleich, wer Trino und wer Presto nutzt, hat das den Ausschlag dafür gegeben, dass es in diesem Artikel um Trino geht.
Abschließend ist es wichtig zu erklären, dass Trino in erster Linie als analytische Datenbank konzipiert wurde. Das bedeutet, dass sie in den meisten Fällen nicht gut für die Transaktionsverarbeitung (OLTP) geeignet ist.
Trino wurde für Data Warehousing und Analytik entwickelt: Datenanalyse, Aggregation großer Datenmengen und Erstellung von Berichten. Diese Arbeitslasten werden oft als Online Analytical Processing (OLAP) bezeichnet.
Nachdem wir das klar gesagt haben, wollen wir uns gleich umdrehen und das Wasser wieder trüben. Mit dem neuesten Data-Lake-Tabellenformat, dem Apache Iceberg, ist OLTP für Trino am Horizont aufgetaucht. Lies mehr darüber in Apache Iceberg : A Primer on medium, in The Definitive Guide to Lakehouse Architecture with Iceberg und Iceberg: ACID Transactions jeweils auf min.io und auch in dieser Einführung in Apache Iceberg in Trino auf starburst.io. Trotzdem solltest du in dieser Richtung mit Vorsicht vorgehen.
Aber jetzt mal im Ernst: Warum solltest du Trino benutzen? Warum solltest du eine halbe Datenbank verwenden, die nicht einmal Daten speichern kann?
1. Es gibt bereits zu viele getrennte Informationssilos in Organisationen
Tatsache ist, dass dein Unternehmen höchstwahrscheinlich keinen weiteren getrennten Datenspeicher braucht. Vielmehr braucht es eine bessere Datenintegration, um ein vollständiges Bild zu erhalten. Wenn Organisationen wachsen, scheinen sie "natürlich" zu unzähligen Informationssilos zu tendieren. Dafür gibt es sowohl technische als auch organisatorische Gründe. Was auch immer der Grund sein mag, es ist weit verbreitet und ein Problem. Hier ist nur ein Artikel in Forbes darüber. Um es kurz zu machen: Die Trennung (auch bekannt als Siloing) scheint von ganz allein zu passieren, denn für die Integration müssen sich Organisationen aktiv bemühen. Siehe auch Informationssilo (Wikipedia).
2. Klassische Datenbanken haben nur ihre Daten, und nur ihre Ausführungsmaschine sitzt darauf
Das ist vielleicht der wichtigste technische Grund, warum es in Unternehmen so viele getrennte Datensilos gibt. Deine klassische relationale Datenbank ist ein Datensilo, und das ist alles, was sie je sein wird. Und wenn du die Daten auch in einem anderen System brauchst, kannst du oft nicht darauf zugreifen, ohne sie zu kopieren, und je nach Situation musst du dafür eine andere Software kaufen oder vielleicht sogar ein ganzes ETL-Projekt in Angriff nehmen.
3. Flexibilität
Trino verhält sich, wie wir bereits festgestellt haben, wie eine Datenbank. Aber es lässt sich unter anderem mit den meisten traditionellen relationalen Datenbanken sowie mit Kafka und Data Lake/Cloud-Technologien verbinden. Sie lässt sich (halbwegs dokumentiert) sogar mit HTTP verbinden, so dass du eine REST-API abfragen und das Ergebnis in einer nahtlosen SQL-Abfrage mit allem Möglichen verbinden kannst. Apropos REST-APIs: Natürlich kannst du eine Verbindung per JDBC herstellen, aber Trino ist nicht nur ein HTTP-Client, sondern auch ein HTTP-Server, siehe Trino REST API. Du kannst also direkt vom Browser aus eine Abfrage stellen, ohne dass ein Anwendungsserver oder ähnliches dazwischengeschaltet werden muss.
Trino ist also ein großartiges Werkzeug für die Datenintegration. Das heißt, du kannst zum Beispiel deinen gesamten ETL-Prozess in der Datenbank erstellen. Und weil es ANSI-SQL-kompatibel ist, können alle deine BI-Tools sofort angeschlossen werden.
Oh, und habe ich es schon erwähnt? Du kannst es auch zu einer In-Memory-Datenbank machen, hier ist der Connector.
4. Geschwindigkeit und Skalierbarkeit
Trino ist eine hochparallele und verteilte Abfrage-Engine, die von Grund auf für effiziente Analysen mit geringer Latenz entwickelt wurde. Die größten Unternehmen der Welt nutzen Trino zur Abfrage von Data Lakes mit einer Größe von mehreren Byte und von riesigen Data Warehouses gleichermaßen. (trino.io)
Wie lässt sich Trino skalieren? Nun, kurz und bündig:
1. Für Datenvolumen und IO:
Du skalierst das zugrunde liegende verteilte Dateisystem wie zum Beispiel das bereits erwähnte Hadoop Distributed File System (HDFS) oder MINIO. Vorausgesetzt natürlich, du fragst einen Data Lake Connector wie Hive, Hudi oder Iceberg ab. Andernfalls musst du das System, mit dem du dich verbindest, skalieren.
2. Zur Skalierung der Ausführung:
Du fügst mehr Trino-Arbeiter hinzu. Trino hat einen Koordinator und viele Arbeiter. Stell dir diese als Computer vor, die große Aufgaben in einzelne Teile aufteilen, um sie parallel zu bearbeiten, und am Ende setzt der Koordinator die Teile zusammen und übergibt dir das Ergebnis.
5. Preisgestaltung
Trino ist Open Source und läuft in der Cloud oder On-Premise, genau wie MINIO oder HDFS. Wenn du also weißt, wie man es anstellt, kannst du etwas Skalierbares für viel weniger Geld bekommen als bei den traditionellen Anbietern, bei denen die Lizenzierung nach CPU-Kern oder Knoten oder was auch immer erfolgt. Du könntest natürlich immer noch kommerzielle Lizenzen und Enterprise-Support benötigen. Auch dafür gibt es Optionen, für Trino von Starburst und für MINIO von MINIO selbst.
In diesem Artikel geht es darum, das Lied von Trino zu singen, aber natürlich gibt es, wo Licht ist, auch Schatten. Der Kürze halber wollen wir hier nur die beiden schlimmsten erwähnen:
1. Bis vor kurzem schlugen Abfragen einfach fehl, wenn ihnen der Speicher ausging. Jetzt gibt es eine Spill-to-Disk-Option. Aber die funktioniert nicht immer sehr gut. (trino.io - Spill-to-Disk)
2. Ein Cluster kann derzeit nur einen Koordinator haben. Das ist schlecht, weil es ein Single Point of Failure ist und auch, weil es irgendwann die Skalierbarkeit einschränken wird. Dieses Problem kann bis zu einem gewissen Grad durch zusätzliche Elemente in der Architektur, wie z. B. Load Balancer, gelöst werden. (Enabling Highly Available Trino Clusters - Goldman Sachs)
Der Begriff "Data Lake" hat einige verschiedene Facetten. Eine davon ist, dass es sich um eine Datenbank handelt, genauer gesagt um eine, bei der es nicht auf eine korrekte Datenmodellierung ankommt, und aus der du dann ein Data Warehouse fütterst, in dem du dann das Chaos aufräumst. Darum geht es hier aber nicht. Vielmehr ist die moderne analytische Datenbank modularisiert, wie du in Abbildung 1 sehen kannst. Der Data Lake ist die unterste von derzeit vier Schichten. Das Tabellenformat ist diejenige, die am spätesten Gestalt angenommen hat.
Die Query Engine (in unserem Fall Trino), die ein bestimmtes Tabellenformat (in unserem Fall Iceberg) in einem bestimmten Dateiformat (in unserem Fall ORC) erwartet, fragt den Objektspeicher (in unserem Fall MINIO) ab. Als Referenz gibt es verschiedene Open-Source-Optionen für jede Ebene.
Abbildung 1: Die Schichten eines Trino-Aufbaus
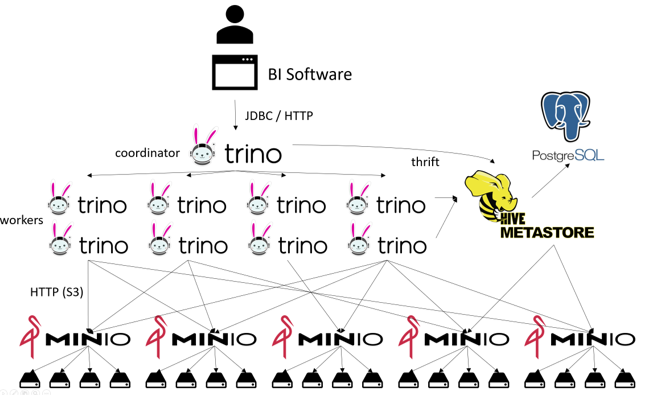
Das Tabellen- und das Dateiformat sind nichts, was du installieren musst, sondern nur Dinge, die die Abfrage-Engine verstehen muss (wie z. B. einen Connector für Trino). Die High-Level-Komponenten sind immer noch die, mit denen wir angefangen haben: Der Speicherteil (Object Store) und der Verarbeitungsteil (Query Engine). In Abbildung 2 sehen wir uns das Ganze aus einer netzwerkähnlichen Perspektive an. Ja, ich mag es, Linien zu zeichnen, und ja, ich habe noch welche vergessen.
Abbildung 2: Das Netzwerk eines Trino-Aufbaus
Womit haben wir es hier also zu tun? Der Nutzer verbindet sich mit seiner BI-Software mit dem Trino-Koordinator. Der Koordinator schaut in den Hive Metastore (das ist nicht die Query Engine aus Abbildung 1, sondern nur ein kleiner Teil davon, siehe Die Solokarriere des Hive Metastore auf medium), um Metadaten zu holen, z. B. über Schema, Relationen und den Verbleib der Daten. Anschließend wird die Arbeit in einzelne Aufgaben aufgeteilt, die auf die Worker verteilt werden. Die Worker holen sich parallel dazu weitere Metadaten zu ihren spezifischen Aufgaben aus dem Hive Metastore.
Die Worker holen sich dann parallel die eigentlichen Daten von den Knoten des verteilten Dateisystems ("Data Lake"), die diese Knoten wiederum parallel von mehreren Festplatten abrufen.
Und ja, bei einigen Operationen interagiert der Metaspeicher direkt mit dem verteilten Dateisystem. Außerdem ist der Metastore selbst nur eine Software, die wiederum ihre Daten irgendwo aufbewahren muss, normalerweise in PosgreSQL. (Ja, ein Teil dieser Datenbank ist eine andere Datenbank)
Jetzt sagen wir: Genug geredet, packen wir's an.
Das sind die Zutaten:
1. Ubuntu Linux
2. Docker
3. Postgres docker image: postgres:latest
4. MINIO docker image: minio/minio
5. Hive Metastore docker image: jiron12/hive-metastore
6. Trino docker image: trinodb/trino
wsl nicht empfohlen. Wenn du unter Windows arbeitest, solltest du Hyper-V verwenden:
Schnell erstellen -> Ubuntu 22.04 LTS
Wenn du bereits mit Ubuntu arbeitest, kannst du diesen Schritt natürlich überspringen, und wir grüßen dich aus unserer sterblichen Welt.
Wenn du dein Ubuntu hast, öffne das Terminal, um Docker zu installieren, starte es und erstelle unser virtuelles Docker-Netzwerk, wir nennen es trino-cluster.
Hol dir den neuesten MINIO-Container, führe ihn aus und verbinde ihn mit unserem virtuellen Netzwerk.
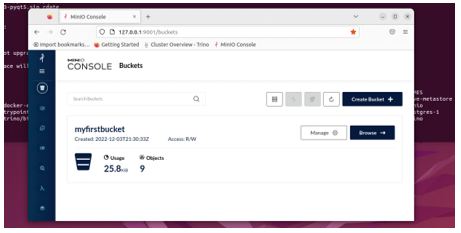
Sobald MINIO läuft (überprüfe das mit sudo docker ps -a), verbinde dich über den Browser mit 127.0.0.1:9001. Für die Anmeldung sind der anfängliche Benutzername und das Passwort minioadmin. Dort erstellst du einen Bucket mit dem Namen myfirstbucket.
Hol dir den neuesten MINIO-Container, führe ihn aus und verbinde ihn mit unserem virtuellen Netzwerk.
Verbinde dich dann mit deiner neuen PostgreSQL-Instanz (zum Beispiel mit DBeaver) und erstelle eine Datenbank mit dem Namen hive_metastore.
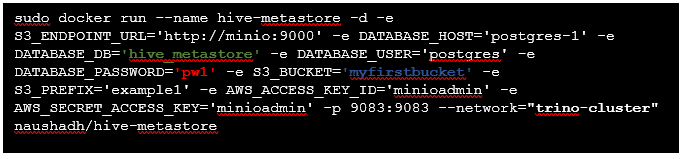
Erhalte und betreibe einen Hive-Metastore-Container direkt in unserem virtuellen Netzwerk.
Ein Lob an naushadh für diesen Container, der "tatsächlich wie angekündigt mit minimalem Aufwand funktioniert".
(hive-metastore/README.md - GitHub)
Schließlich richten wir Trino selbst ein und fügen es dem virtuellen Netzwerk hinzu.
Wenn alles läuft, solltest du den STATUS "Up" für jeden der Container haben, wenn du
Gehen Sie dann in den Trino-Container, den Sie gerade mit
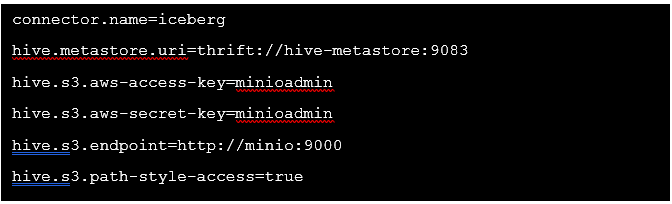
Und erstelle eine Datei /etc/trino/catalog/iceberg.properties mit folgendem Inhalt:
Starte danach den Trino-Container neu. Wenn du dich jetzt mit Trino verbindest, solltest du ein Schema wie dieses erstellen können (wieder mit DBeaver):
Vielleicht willst du sogar ein paar Tabellen erstellen. Danach: Schau nach, ob du jetzt Daten in deinem MINIO-Eimer hast.
Herzlichen Glückwunsch! Du gehörst jetzt zu der sehr exklusiven Gruppe von Menschen, die ein Trino-Setup betreiben. Das bedeutet, dass du Cloud-Technologien genutzt hast, um eine verteilte Datenbank in einem Data Lake zu erstellen. Jetzt kannst du damit spielen, was du willst.
Natürlich haben wir jetzt nur noch einen Speicher- und einen Verarbeitungsknoten. Das funktioniert ganz gut, aber wenn wir das erweitern wollen, sind ein paar weitere Schritte nötig. Und natürlich bräuchten wir auch mehr Hardware, damit es Sinn macht.
Wir haben beschrieben, was Trino ist, und dann Trino als eine großartige Option für moderne Big Data-Analysen vorgestellt. Wir haben darüber gesprochen, dass Informationen im Unternehmen dazu neigen, getrennt zu werden, obwohl wir eigentlich eine Integration wollen, und Trino kann das sehr gut. Aber, um auf den Titel zurückzukommen, genau wie beim Aufbau von Nationen kann Integration auch in der Unternehmensorganisation schwierig sein. Wir sollten uns alle darum bemühen, aber manchmal können wir vorerst nicht den ganzen Weg dorthin gehen. Und in diesem Spannungsfeld zwischen Segregation und Integration hat Trino noch eine dritte Antwort: Die Föderation. Lass deine Daten dort, wo sie sind, in dem System, in dem sie aufgewachsen sind. Aber verbinde sie trotzdem mit allen anderen Daten in deinem Unternehmen, damit du mit deinen Daten arbeiten kannst, als wären sie alle an einem Ort.
Danach sind wir auch auf einige Schwächen von Trino eingegangen. Dann haben wir gezeigt, wie die Schichten eines Trino-Setups aussehen können und wie die Landschaft typischerweise aussieht. Schließlich haben wir versucht, Trino einzurichten, um damit zu spielen. Ich hoffe, es hat dir gefallen!
Wenn du an dieser Stelle weitere Fragen hast, kannst du uns gerne kontaktieren: Analytics Beratung und Business Intelligence | Swisscom
Wenn du daran interessiert bist, unsere Kunden über ein breites Spektrum an analytischer Informationstechnologie zu beraten, dann sieh dir unsere Stellenangebote an.

Senior Data & Analytics Consultant
Finde deinen Job oder die Karrierewelt, die zu dir passt. In der du mitgestalten und dich weiterentwickeln willst.
Was du draus machst, ist was uns ausmacht.