Business Intelligence
La Fédération de Trino
Une réponse aux tensions entre séparation et intégration de l’information.
Business Intelligence
Une réponse aux tensions entre séparation et intégration de l’information.
Eh bien, Trino est une demi-base de données, c'est ce qu'il est. Et bien que beaucoup pensent que c'est plutôt étrange et inutile, c'est justement l'une de ses plus grandes forces. Trino est une base de données qui ne contient pas de données. C'est pourquoi il n'est pas présenté sur le site comme une base de données, mais comme un programme de requête SQL:
Trino est un moteur de requêtes SQL distribué, conçu pour interroger de grands ensembles de données répartis sur une ou plusieurs sources de données hétérogènes.
Cela signifie que Trino se comporte comme une base de données, mais il le fait en traitant des données qui sont stockées à peu près partout, sauf en lui-même. C'est pourquoi il n'est qu'à moitié une base de données. Et c'est intéressant, car la base de données relationnelle classique travaille presque exclusivement avec des données stockées en son sein, et l'accès aux données stockées en son sein se fait exclusivement via son propre logiciel. Trino accède aux données presque partout (regarde la liste longue et croissante des connecteurs vers d'autres technologies), et deuxièmement, ces données peuvent aussi être récupérées directement depuis d'autres systèmes. Cela rend Trino plus intégré, voire même plus intégratif. Si tu as deux ou plusieurs connecteurs vers différents systèmes, tu peux aussi "accéder aux données de plusieurs systèmes en une seule requête. Par exemple, connecte les données historiques des journaux stockées dans un stockage d'objets S3 avec les données des clients stockées dans une base de données relationnelle MySQL". (trino.io) C'est ce qu'on appelle la fédération de requêtes (voir le titre de cet article). Ce n'est pas la panacée et cela peut avoir un impact sur la performance des requêtes, ce qui dépend aussi du système source, mais cela peut parfois être une bonne option.
Si nous remontons dans l'histoire de l'informatique (analytique), nous constatons tout d'abord que ce concept de séparation du stockage et du calcul n'est pas si nouveau pour les bases de données. En fait, ce concept existe depuis très longtemps, mais il est devenu beaucoup plus important dans l'analytique, probablement à partir de Hadoop, qui a été publié pour la première fois en 2006.
Le cœur d'Apache Hadoop se compose d'une partie stockage, connue sous le nom de Hadoop Distributed File System (HDFS), et d'une partie traitement, qui est un modèle de programmation MapReduce.
Les termes "calcul", "traitement" et aussi "exécution" sont synonymes dans ce contexte. Trino, comme nous l'avons déjà mentionné, traite des données, mais les données ne sont pas stockées en elles-mêmes.
Contrairement à Hadoop, Trino est définitivement et complètement SQL first. Le titre du livre blanc original est même "Presto: SQL pour tout". Attends, qu'est-ce que "Presto"? Presto est le nom original du projet qui s'appelle maintenant Trino. Et ici, il y a une triste histoire à raconter. Le projet Presto a été lancé sur Facebook en 2014. Mais les développeurs initiaux et Facebook se sont séparés en 2018 pour des questions de gestion et de contrôle du projet open source. Tu trouveras la longue histoire ici. En gros, il y a maintenant Trino et Presto, qui développent presque le même logiciel dans deux projets distincts. Et bien que le code soit parfois partagé entre les deux, cette division a certainement entravé le progrès. De plus, la question se pose naturellement: lequel utiliser ? Un cas clair de même et pourtant différent. Nous pouvons comparer le pouls des deux dépôts sur GitHub et conclure que le projet Trino (avec les développeurs originaux) est toujours plus fort que le projet Presto (que Facebook a transféré à la Linux Foundation après les retombées). Bien sûr, ce n'est pas la science infuse, mais avec la comparaison de qui utilise Trino et qui utilise Presto, cela a fait pencher la balance en faveur de Trino dans cet article.
Pour finir, il est important d'expliquer que Trino a été conçu en premier lieu comme une base de données analytique. Cela signifie que dans la plupart des cas, elle n'est pas bien adaptée au traitement des transactions (OLTP).
Trino a été conçu pour l'entreposage de données et l'analytique : Analyse des données, agrégation de grandes quantités de données et création de rapports. Ces charges de travail sont souvent appelées traitement analytique en ligne (OLAP).
Après avoir dit cela clairement, nous voulons tout de suite nous retourner et troubler à nouveau l'eau. Avec le dernier format de table Data-Lake, Apache Iceberg, l'OLTP pour Trino est apparu à l'horizon. Lis-en plus dans Apache Iceberg: A Primer on medium, dans The Definitive Guide to Lakehouse Architecture with Iceberg et Iceberg: ACID Transactions respectivement sur min.io et aussi dans cette introduction à Apache Iceberg dans Trino sur starburst.io. Néanmoins, tu devrais avancer avec prudence dans cette direction.
Mais sérieusement maintenant: pourquoi devrais-tu utiliser Trino? Pourquoi utiliser une demi-base de données qui ne peut même pas stocker de données?
1. Il y a déjà trop de silos d'information séparés dans les organisations
Le fait est que ton entreprise n'a très probablement pas besoin d'un autre stockage de données séparé. Il faut plutôt une meilleure intégration des données pour obtenir une image complète. Lorsque les organisations grandissent, elles semblent avoir "naturellement" tendance à avoir d'innombrables silos d'information. Il y a des raisons techniques et organisationnelles à cela. Quelle que soit la raison, elle est très répandue et constitue un problème. Voici juste un article de Forbes à ce sujet. Pour faire court : La séparation (également connue sous le nom de siloing) semble se faire toute seule, car pour l'intégration, les organisations doivent faire des efforts actifs. Voir aussi Silo d'information (Wikipedia).
2. Les bases de données classiques n'ont que leurs données, et seul leur moteur d'exécution est assis dessus
C'est peut-être la raison technique la plus importante pour laquelle il y a tant de silos de données séparés dans les entreprises. Ta base de données relationnelle classique est un silo de données, et c'est tout ce qu'elle sera jamais. Et si tu as aussi besoin des données dans un autre système, tu ne peux souvent pas y accéder sans les copier et, selon la situation, tu dois acheter un autre logiciel pour cela ou peut-être même t'attaquer à un projet ETL entier.
3. Flexibilité
Trino, comme nous l'avons déjà établi, se comporte comme une base de données. Mais il se connecte, entre autres, à la plupart des bases de données relationnelles traditionnelles, ainsi qu'à Kafka et aux technologies data lake/cloud. Elle (en quelque sorte semi-documentée) se connecte même à HTTP, de sorte que tu peux interroger une API REST et joindre le résultat avec ce que tu veux dans une requête SQL sans faille. Parler de l'API REST : Bien que tu puisses te connecter via JDBC, Trino n'est pas seulement un client HTTP, c'est aussi un serveur HTTP, voir l'API REST de Trino. Ainsi, tu pourrais l'interroger directement à partir du navigateur, aucun serveur d'application ou autre nécessaire entre les deux.
Trino est donc un excellent outil d'intégration de données. En d'autres termes, tu pourrais par exemple créer tout ton processus ETL dans la base de données. Et parce qu'il est conforme à ANSI SQL, tous tes outils de BI peuvent se connecter directement.
Oh, et est-ce que j'ai déjà mentionné? Tu peux aussi en faire une base de données en mémoire, voici le connecteur.
4. Vitesse et évolutivité
Trino is a highly parallel and distributed query engine, that is built from the ground up for efficient, low latency analytics. The largest organizations in the world use Trino to query exabyte scale data lakes and massive data warehouses alike. (trino.io)
Comment Trino s'adapte-t-il à l'échelle? En quelques mots:
1. Pour le volume de données et IO:
Tu mets à l'échelle le système de fichiers distribué sous-jacent, comme par exemple le système de fichiers distribué Hadoop (HDFS) déjà mentionné ou MINIO. A condition, bien sûr, que tu interroges un connecteur de data lake comme Hive, Hudi ou Iceberg. Dans le cas contraire, tu dois mettre à l'échelle le système auquel tu te connectes.
2. Pour mettre à l'échelle l'exécution:
Tu ajoutes plus de travailleurs Trino. Trino a un coordinateur et de nombreux travailleurs. Imagine-les comme des ordinateurs qui divisent de grandes tâches en parties individuelles pour les traiter en parallèle, et à la fin, le coordinateur assemble les parties et te donne le résultat.
5. Fixation des prix
Trino est open source et fonctionne dans le cloud ou sur site, tout comme MINIO ou HDFS. Donc, si tu sais comment t'y prendre, tu peux obtenir quelque chose d'évolutif pour beaucoup moins d'argent que les fournisseurs traditionnels, où la licence se fait par cœur de processeur ou par nœud ou autre. Bien sûr, tu peux toujours avoir besoin de licences commerciales et d'un support d'entreprise. Pour cela aussi, il existe des options, pour Trino de Starburst et pour MINIO de MINIO lui-même.
Le but de cet article est de chanter la chanson de Trino, mais bien sûr, là où il y a de la lumière, il y a aussi des ombres. Par souci de brièveté, nous ne mentionnerons ici que les deux pires:
1. Jusqu'à récemment, les requêtes échouaient simplement lorsqu'elles manquaient de mémoire. Maintenant, il y a une option spill-to-disk. Mais elle ne fonctionne pas toujours très bien. (trino.io - Spill-to-Disk)
2. Actuellement, un cluster ne peut avoir qu'un seul coordinateur. C'est mauvais parce que c'est un point unique de défaillance et aussi parce qu'à un moment donné, cela limitera l'extensibilité. Ce problème peut être résolu dans une certaine mesure par des éléments supplémentaires dans l'architecture, comme par exemple les load balancers. (Enabling Highly Available Trino Clusters - Goldman Sachs)
Le terme "Data Lake" a plusieurs facettes. L'une d'entre elles est qu'il s'agit d'une base de données, plus précisément d'une base de données qui ne nécessite pas une modélisation correcte des données, et à partir de laquelle tu alimentes un entrepôt de données dans lequel tu nettoies ensuite le chaos. Mais ce n'est pas de cela qu'il s'agit. La base de données analytique moderne est plutôt modularisée, comme tu peux le voir dans l'illustration 1. Le Data Lake est la couche la plus basse des quatre couches actuelles. Le format de table est celui qui a pris forme le plus tard.
Le moteur de requête (dans notre cas Trino), qui attend un certain format de table (dans notre cas Iceberg) dans un certain format de fichier (dans notre cas ORC), interroge le stockage d'objets (dans notre cas MINIO). Comme référence, il existe différentes options open-source pour chaque niveau.
Figure 1: Les couches d'une construction Trino
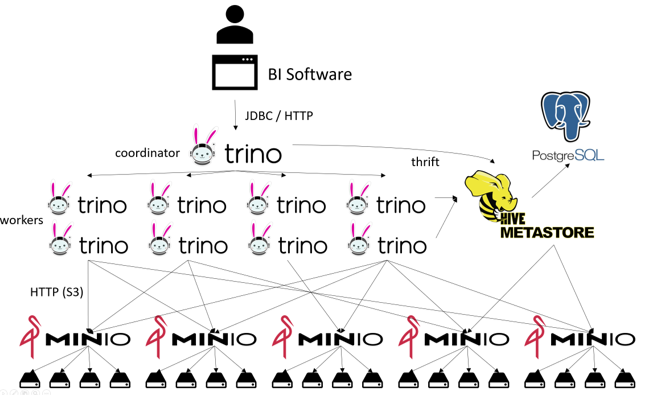
Le format de table et de fichier n'est pas quelque chose que tu dois installer, mais seulement des choses que le moteur de requête doit comprendre (comme un connecteur pour Trino). Les composants de haut niveau sont toujours ceux avec lesquels nous avons commencé: La partie mémoire (Object Store) et la partie traitement (Query Engine). Dans l'illustration 2, nous regardons tout cela d'une perspective semblable à celle d'un réseau. Oui, j'aime bien dessiner des lignes, et oui, j'en ai encore oublié.
Illustration 2: Le réseau d'une construction Trino
A quoi avons-nous donc affaire ici? L'utilisateur se connecte avec son logiciel BI au coordinateur Trino. Le coordinateur regarde dans le Hive Metastore (ce n'est pas le moteur de recherche de l'image 1, mais seulement une petite partie, voir La carrière en solo du Hive Metastore sur medium) pour récupérer des métadonnées, par exemple sur le schéma, les relations et l'endroit où se trouvent les données. Ensuite, le travail est divisé en tâches individuelles qui sont réparties entre les travailleurs. Les travailleurs récupèrent en parallèle d'autres métadonnées sur leurs tâches spécifiques à partir du Hive Metastore.
Les travailleurs récupèrent ensuite en parallèle les données réelles des nœuds du système de fichiers distribué ("Data Lake"), que ces nœuds récupèrent à leur tour en parallèle de plusieurs disques durs.
Et oui, pour certaines opérations, le métaspace interagit directement avec le système de fichiers distribué. De plus, le métastore lui-même n'est qu'un logiciel qui, à son tour, doit stocker ses données quelque part, généralement dans PosgreSQL. (Oui, une partie de cette base de données est une autre base de données).
Maintenant, nous disons : Assez parlé, faisons-le.
Voici les ingrédients:
1. Ubuntu Linux
2. Docker
3. Postgres docker image: postgres:latest
4. MINIO docker image: minio/minio
5. Hive Metastore docker image: jiron12/hive-metastore
6. Trino docker image: trinodb/trino
wsl non recommandé. Si tu travailles sous Windows, tu devrais utiliser Hyper-V:
Créer rapidement -> Ubuntu 22.04 LTS
Si tu travailles déjà avec Ubuntu, tu peux bien sûr sauter cette étape, et nous te saluons depuis notre monde mortel.
Si tu as ton Ubuntu, ouvre le terminal pour installer Docker, démarre-le et crée notre réseau virtuel Docker, nous l'appelons trino-cluster.
Récupère et exécute le dernier conteneur MINIO et connecte-le à notre réseau virtuel.
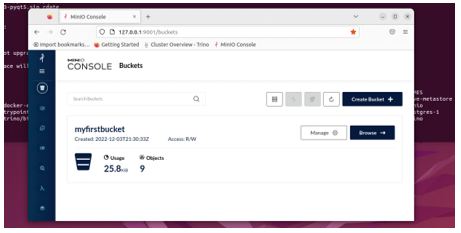
Une fois que MINIO fonctionne (vérifie avec sudo docker ps -a), connecte-toi via le navigateur à 127.0.0.1:9001. Pour la connexion, le nom d'utilisateur initial et le mot de passe sont minioadmin. Là, tu crées un bucket avec le nom myfirstbucket.
Obtiens le dernier conteneur MINIO, exécute-le et connecte-le à notre réseau virtuel.
Connecte-toi ensuite à ta nouvelle instance PostgreSQL (par exemple avec DBeaver) et crée une base de données nommée hive_metastore.
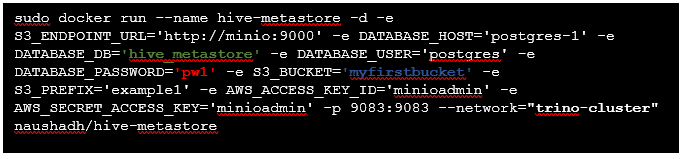
Obtiens et exploite un conteneur métastore Hive directement dans notre réseau virtuel.
Bravo à naushadh pour ce conteneur qui "fonctionne effectivement comme annoncé avec un minimum d'effort".
(hive-metastore/README.md - GitHub)
Enfin, nous configurons Trino nous-mêmes et l'ajoutons au réseau virtuel.
Si tout fonctionne, tu devrais avoir le STATUS "Up" pour chacun des conteneurs, si tu
Va ensuite dans le conteneur Trino que tu viens d'ouvrir avec
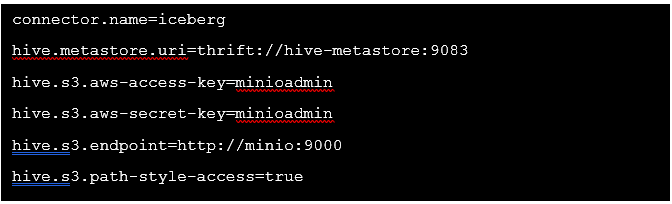
Et crée un fichier /etc/trino/catalog/iceberg.properties avec le contenu suivant:
Redémarre ensuite le conteneur Trino. Si tu te connectes maintenant à Trino, tu devrais pouvoir créer un schéma comme celui-ci (à nouveau avec DBeaver):
Tu veux peut-être même créer des tableaux. Après: vérifie si tu as maintenant des données dans ton seau MINIO.
Toutes nos félicitations ! Tu fais désormais partie du groupe très exclusif de personnes qui gèrent une configuration Trino. Cela signifie que tu as utilisé les technologies cloud pour créer une base de données distribuée dans un data lake. Maintenant, tu peux jouer avec ce que tu veux.
Bien sûr, nous n'avons maintenant qu'un nœud de mémoire et un nœud de traitement. Cela fonctionne très bien, mais si nous voulons l'étendre, quelques étapes supplémentaires sont nécessaires. Et bien sûr, nous aurions besoin de plus de matériel pour que cela ait un sens.
Nous avons décrit ce qu'est Trino, puis nous avons présenté Trino comme une option formidable pour l'analyse moderne des Big Data. Nous avons parlé du fait que les informations dans l'entreprise ont tendance à être séparées, alors qu'en fait nous voulons une intégration, et Trino le fait très bien. Mais, pour en revenir au titre, tout comme dans la construction de nations, l'intégration peut être difficile dans l'organisation de l'entreprise. Nous devrions tous nous y efforcer, mais parfois nous ne pouvons pas aller jusqu'au bout pour le moment. Et dans cette tension entre ségrégation et intégration, Trino a une troisième réponse : la fédération. Laisse tes données là où elles sont, dans le système dans lequel elles ont grandi. Mais connecte-les quand même à toutes les autres données de ton entreprise, pour que tu puisses travailler avec tes données comme si elles étaient toutes au même endroit.
Ensuite, nous avons également abordé quelques faiblesses de Trino. Ensuite, nous avons montré à quoi peuvent ressembler les couches d'une configuration Trino et à quoi ressemble typiquement le paysage. Enfin, nous avons essayé de configurer Trino pour pouvoir jouer avec. J'espère que cela t'a plu!
WSi tu as d'autres questions à ce stade, n'hésite pas à nous contacter: Analytics Beratung und Business Intelligence | Swisscom
Si tu es intéressé par le fait de conseiller nos clients sur un large éventail de technologies de l'information analytique, consulte nos offres d'emploi.

Senior Data & Analytics Consultant
Trouve ton travail ou le monde de la carrière qui te convient. Dans lequel tu veux participer à la création et te développer.
Ce que tu en fais, c'est ce qui nous définit.